

On Nov. 13, Facebook announced with great fanfare that it was taking down substantially more posts containing hate speech from its platform than ever before.
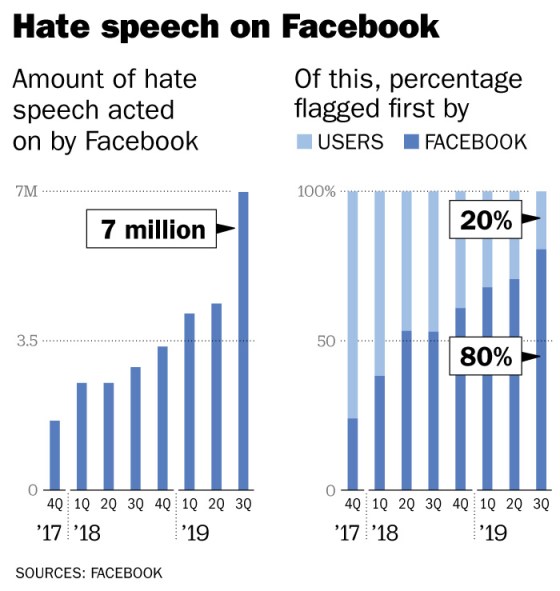
Facebook removed more than seven million instances of hate speech in the third quarter of 2019, the company claimed, an increase of 59% against the previous quarter. More and more of that hate speech (80%) is now being detected not by humans, they added, but automatically, by artificial intelligence.
The new statistics, however, conceal a structural problem Facebook is yet to overcome: not all hate speech is treated equally.
The algorithms Facebook currently uses to remove hate speech only work in certain languages. That means it has become easier for Facebook to contain the spread of racial or religious hatred online in the primarily developed countries and communities where global languages like English, Spanish and Mandarin dominate.
But in the rest of the world, it’s as difficult as ever.
Facebook tells TIME it has functional hate speech detection algorithms (or “classifiers,” as it calls them internally) in more than 40 languages worldwide. In the rest of the world’s languages, Facebook relies on its own users and human moderators to police hate speech.
Unlike the algorithms that Facebook says now automatically detect 80% of hateful posts without needing a user to have reported them first, these human moderators do not regularly scan the site for hate speech themselves. Instead, their job is to decide whether posts that users have already reported should be removed.
Languages spoken by minorities are the hardest-hit by this disparity. It means that racial slurs, incitements to violence and targeted abuse can spread faster in the developing world than they do at present in the U.S., Europe and elsewhere.
India, the second-most populous country in the world with more than 1.2 billion people and nearly 800 languages, offers an insight into this problem.
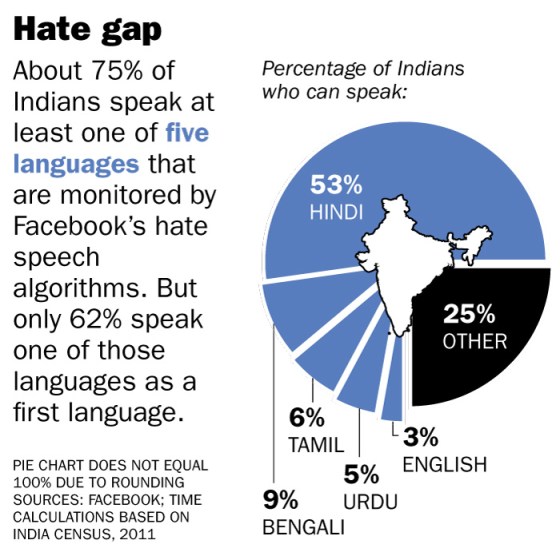
Facebook declined to share a full list of languages in which it has working hate speech detection algorithms. But the company tells TIME that out of the 22 official languages of India, only four — Hindi, Bengali, Urdu and Tamil — are covered by Facebook’s algorithms. Some 25% of India’s population do not speak at least one of those four languages or English, and about 38% don’t speak one as their first language, according to a TIME analysis of the 2011 Indian census.
In the state of Assam, in northeastern India, this gap in Facebook’s systems has allowed for violent extremism to flourish — unchecked by regulators and accelerated by the power Facebook gives anybody to share text, images and video widely.
In Assam, the global advocacy group Avaaz has identified an ongoing campaign of hate by the Assamese-speaking, largely Hindu, majority against the Bengali-speaking, largely Muslim, minority. In a report published in October, Avaaz detailed Facebook posts calling Bengali Muslims “parasites,” “rats” and “rapists,” and calling for Hindu girls to be poisoned to stop Muslims from raping them. The posts were viewed at least 5.4 million times. The U.N. has called the situation there a “potential humanitarian crisis.”
Facebook confirmed to TIME that it does not have an algorithm for detecting hate speech in Assamese, the main language spoken in Assam. Instead of automatically detecting hate speech in Assamese, Facebook employs an unspecified number of human moderators around the clock who speak the language. But those moderators, for the most part, only respond to posts flagged by users.
Campaigners say Facebook’s reliance on user reports of hate speech in languages where it does not have working algorithms puts too much of a burden on these victims of hate speech, who are often not highly educated and already from marginalized communities. “In the Assamese context, the minorities most directly targeted by hate speech on Facebook often lack online access or the understanding of how to navigate Facebook’s flagging tools. No one else is reporting it for them either,” the Avaaz report says. “This leaves Facebook with a huge blindspot,” Alaphia Zoyab, a senior campaigner at Avaaz, tells TIME.
The solution, Zoyab says, isn’t less human involvement, it’s more: more Facebook employees doing proactive searches for hate speech, and a concerted effort to build a dataset of Assamese hate speech. “Unless Facebook chooses to become smarter about understanding the societies in which it operates, and ensures it puts human beings on the case to proactively ‘sweep’ the platform for violent content, in some of these smaller languages we’re going to continue in this digital dystopia of dangerous hate,” she tells TIME.
Technical issues
Facebook says the reason it can’t automatically detect hate speech in Assamese — and other small languages — is because it doesn’t have a large enough dataset to train the artificial intelligence program that would do so.
In a process called machine learning, Facebook trains its computers to grade posts on a spectrum of hatefulness by giving them tens or hundreds of thousands of examples of hate speech. In English, which has 1.5 billion speakers, that’s easy enough. But in smaller languages like Assamese, which has only 23.6 million speakers according to the 2011 Indian census, that becomes harder. Add the fact that not many hateful posts in Assamese are flagged as hate speech in the first place, and it becomes very difficult to train a program to detect hatred in Assamese.
But campaigners say this doesn’t make the current situation in Assam inevitable. When hate speech against the Rohingya minority in Myanmar spread virulently via Facebook in Burmese (a language spoken by some 42 million people) Facebook was slow to act because it had no hate-speech detection algorithm in Burmese, and few Burmese-speaking moderators. But since the Rohingya genocide, Facebook has built a hate-speech classifier in Burmese by pouring resources toward the project. It paid to hire 100 Burmese-speaking content moderators, who manually built up a dataset of Burmese hate speech that was used to train an algorithm.
Facebook declined to say how many Assamese-speaking moderators it employs, after multiple requests from TIME. In a statement, Facebook said: “We don’t break down the number of content reviewers by language, in large part because the number alone isn’t representative of the people working on any given language or issue and the number changes based on staffing needs. We base our staffing on a number of different factors, including the geopolitical situation on the ground and the volume of content posted in a specific language.”
Facebook tells TIME that it has a list of countries in which it has prioritized its work preventing what it calls “offline harms,” which it defines as real-world physical violence. Myanmar, Sri Lanka, India, Libya, Ethiopia, Syria, Cameroon, the Democratic Republic of Congo and Venezuela are on that list, a spokesperson said.
The company also revealed to TIME some more of the 40-plus languages in which it has working hate speech detection algorithms. They include Mandarin and Arabic, and the two official languages of Sri Lanka: Sinhalese and Tamil. The company is currently building a hate speech classifier in Punjabi — another official Indian language that has more than 125 million speakers around the world.
Facebook has also declined to disclose the success rate of individual language algorithms. So, while globally Facebook’s algorithms now detect 80% of hate speech before it’s reported by a user, it is impossible to tell whether this is an average that masks lower success rates in some languages compared to others.
Two Facebook officials — one engineer who works on hate speech algorithms, and one member of Facebook’s “strategic response team” — told TIME that Facebook was building classifiers in several new languages, but did not want to set them loose on the site until they were more accurate, in order to avoid taking down posts that aren’t hateful.
But even when their algorithms flag hate speech content, Facebook says, human moderators always make the final decision on whether to remove it. Facebook says its moderators typically respond to reports within 24 hours. During that time, posts flagged as hateful remain online.
In “more than 50” languages, Facebook says, it has moderators working 24 hours a day, seven days a week. But there is “significant overlap” between those 50-plus languages and the 40-plus languages in which an algorithm is currently active, Facebook says. In still more languages, Facebook employs part-time moderators.
Because Facebook does not break down the number of content moderators by language, it is also hard to tell if there are also discrepancies between languages when it comes to how quickly and efficiently hateful posts are removed. According to Avaaz, minority languages are overlooked when it comes to the speed of moderation, too. When Avaaz reported 213 of the “clearest examples” of hateful posts in Assamese to Facebook, moderators eventually removed 96 within 24 hours. But the other 117 examples of “brazen hate speech” remain on the site, according to Zoyab.
Other observers question the validity of building an automated system that, they fear, will eventually outsource to machines the decisions on what kind of speech is acceptable. “Free speech implications should be extremely worrisome to everybody, since we do not know what Facebook is leaving up and taking down,” says Susan Benesch, the executive director of the Dangerous Speech Project, a non-profit that studies how public speech can cause real-world violence. “They are taking down millions of pieces of content every day, and you do not know where they are drawing the line.”
“Preventing it from being posted in the first place,” Benesch says, “would be much, much more effective.”
— Additional reporting by Emily Barone and Lon Tweeten/New York

No comments:
Post a Comment